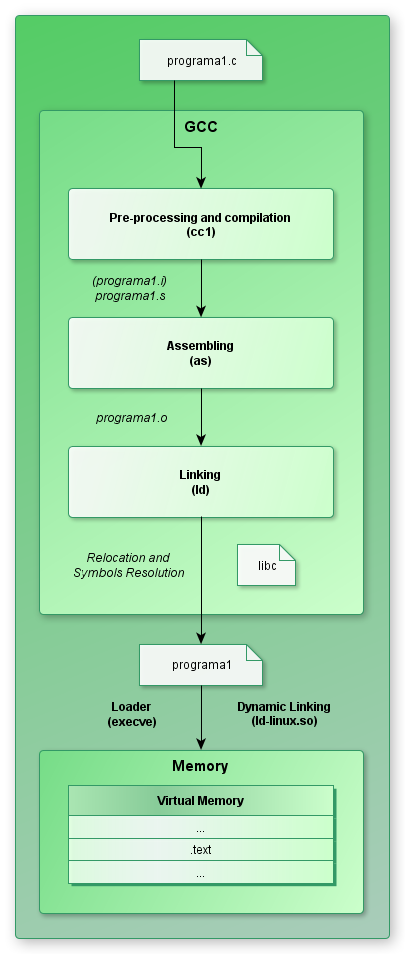
Ao finalizar o primeiro post, disse-lhes que neste iniciaríamos uma abordagem prática da engenharia reversa que possibilitaria um entendimento objetivo da estrutura ELF. Contudo, optei por inverter essa ordem, sendo que agora daremos início diretamente pelo ELF, a despeito de que a análise da sua estrutura, mesmo que realizada minimamente, em si já é um meio de reversão, e, somente empós, fá-la-emos propriamente lidando com o respectivo binário.
Preciso também fazer menção às correções que efetuei no
primeiro post da sequência. Graças ao
Ygor Parreira (valeu, dmr!), identifiquei informações desatualizadas na descrição do processo de compilação. Por isso, para que não haja prejuízo no estudo, a releitura se faz obrigatória.
Os arquivos deste post estão disponíveis no
GitHub.
ELF (Pointed Ears)
O ELF (Executable and Linking Format) é um formato (estrutura) que especifica a composição e organização de um arquivo-objeto (representação binária, resultado do procedimento de montagem) para que este seja funcional ao sistema operacional que o utiliza; é, em miúdos, um mapa que permite a criação/utilização correta, através dos linker e loader, dos arquivos com esse padrão.
Originalmente desenvolvido e publicado pelos USL (UNIX System Laboratories) como parte da ABI, o ELF se tornou padrão em vários sistemas operacionais Unix-like, substituindo formatos antigos como a.out e COFF. Hoje em dia é utilizado também em sistemas operacionais não-Unix como OpenVMS, BeOS e Haiku, assim como em videogames, celulares, tablets, roteadores, televisões etc.
No tocante à introdução (pg. 45) do System V - Application Binary Interface (ABI), Ed. 4.1 (documento que descreve a interface entre o programa e o sistema operacional ou outro programa), faço uma ressalva à afirmação "o arquivo-objeto é criado pelo assembler 'e' link editor", pois, contrariedade a essa regra foi demonstrada na criação do crackme.03, ao ser desprezada a lincagem. De toda sorte, num processo normal de compilação é correto se dizer que o procedimento de lincagem estará presente.
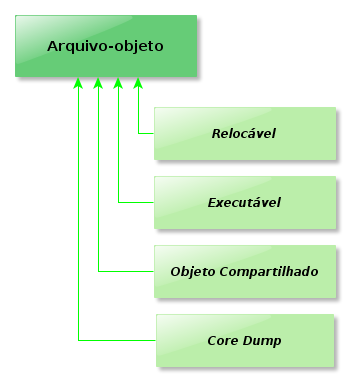
Tipos de ELF (Middle-Earth, D&D, ...)
Discorramos um pouco sobre os tipos mais comuns de arquivos-objeto ELF.
Relocável
O arquivo-objeto relocável possui código e dados prontos para a combinação com outros arquivos-objeto, que comporão um executável ou um objeto compartilhado.
Vejamos abaixo o programa1.o.
# gcc programa1.c -m32 -c
programa1.o: ELF 32-bit LSB relocatable, Intel 80386, version 1 (SYSV), not stripped
# readelf-h programa1.o | grep Type
Type: REL (Relocatable file)
# readelf -r programa1.o
Relocation section '.rel.text' at offset 0x3ec contains 2 entries:
Offset Info Type Sym.Value Sym. Name
0000000c 00000501 R_386_32 00000000 .rodata
00000011 00000a02 R_386_PC32 00000000 puts
Relocation section '.rel.eh_frame' at offset 0x3fc contains 1 entries:
Offset Info Type Sym.Value Sym. Name
00000020 00000202 R_386_PC32 00000000 .text
Nesse primeiro exemplo, o gcc compilou e montou o binário relocável programa1.o que ainda não teve os endereços para execução informados em sua estrutura (ELF), assim como também não teve resolvidas as referências de símbolos.
Com o readelf constatamos que os endereços não foram definidos.
# readelf -S programa1.o
There are 13 section headers, starting at offset 0x11c:
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 0] NULL 00000000 000000 000000 00 0 0 0
[ 1] .text PROGBITS 00000000 000034 00001c 00 AX 0 0 4
[ 2] .rel.text REL 00000000 0003ec 000010 08 11 1 4
[ 3] .data PROGBITS 00000000 000050 000000 00 WA 0 0 4
[ 4] .bss NOBITS 00000000 000050 000000 00 WA 0 0 4
[ 5] .rodata PROGBITS 00000000 000050 00000c 00 A 0 0 1
...
E através do
nm temos a lista de todos os símbolos; a serem resolvidos.
# nm -a programa1.o
00000000 b .bss
...
00000000 d .data
...
00000000 t .text
00000000 T main
...
Segue outro exemplo utilizando o relocável programa2.o (versão em assembly do programa1).
# nasm -f elf32 programa2.asm
# readelf -r programa2.o
Relocation section '.rel.text' at offset 0x260 contains 1 entries:
Offset Info Type Sym.Value Sym. Name
0000000b 00000201 R_386_32 00000000 .data
Executável
Este tipo de arquivo-objeto contém as informações necessárias à criação de sua respectiva imagem de processo por meio da função (syscall) exec.
# gcc programa1.c -m32 -o programa1
# ./programa1
Hello World
# file programa1
programa1: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=df0b281079aace57fec72570a37ba345c7679a59, not stripped
# readelf -S programa1
There are 30 section headers, starting at offset 0x7f0:
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
...
[12] .plt PROGBITS 080482c0 0002c0 000040 04 AX 0 0 16
[13] .text PROGBITS 08048300 000300 000194 00 AX 0 0 16
[14] .fini PROGBITS 08048494 000494 000014 00 AX 0 0 4
[15] .rodata PROGBITS 080484a8 0004a8 000014 00 A 0 0 4
...
Pode ser visto acima que o arquivo-objeto do tipo executável teve sua estrutura relocada.
Podemos confirmar isso, também, através do cabeçalho ELF. Vejam que o objeto relocável não possui endereço de entrada.
# readelf -h programa1.o | grep Entry
Entry point address: 0x0
Porém, possui quando executável.
# readelf -h programa1 | grep Entry
Entry point address: 0x8048300
No programa1, a lincagem (collect2) amarrou (symbol binding) as referências locais e as concernentes às bibliotecas dinâmicas, e relocou as estruturas de dados, prontificando o arquivo-objeto à execução.
Escrutinemos mais ainda com a tool
ldd que nos lista as bibliotecas compartilhadas necessárias ao executável.
# ldd programa1
linux-gate.so.1 (0xf76ea000)
libc.so.6 => /usr/lib32/libc.so.6 (0xf751b000)
/lib/ld-linux.so.2 (0xf76eb000)
Vemos acima que o programa1.c faz uso da biblioteca compartilhada libc (função printf).
O
programa2 (assembly), entretanto, tem suas peculiaridades.
# ld -m elf_i386 programa2.o -o programa2
./programa2
Hello World
# readelf -r programa2
There are no relocations in this file.
# file programa2
programa2: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), statically linked, not stripped
# ldd programa2
not a dynamic executable
O ldd não apresenta nenhuma biblioteca compartilhada, uma vez que o programa2 só faz uso de syscalls. Tal fato denota que não foi necessário se efetuar a combinação com outros arquivos-objeto, restando apenas perfazer os demais procedimentos como a resolução das referências de símbolos locais e a relocação. É importante destacar que o programa1, diferentemente do programa2, será também lincado
dinamicamente a cada nova instanciação, por conta de seus símbolos indefinidos.
Objeto Compartilhado
Este arquivo-objeto detém código e dados apropriados para duas situações de lincagem.
Objeto compartilhado combinado com outro objeto compartilhado e/ou com relocável.
Inicialmente, engendremos o arquivo-objeto compartilhado libfoo1.so.
# readelf -h foo1.o | grep Type
Type: REL (Relocatable file)
# gcc -shared -m32 -o libfoo1.so foo1.o
# readelf -h libfoo1.so | grep Type
Type: DYN (Shared object file)
Veja abaixo a criação a partir da combinação do arquivo-objeto compartilhado libfoo1.so com o relocável foo2.o.
# gcc -c -fPIC -m32 foo2.c -o foo2.o
# gcc -shared -m32 -o libfoo2.so foo2.o libfoo1.so
# readelf -h libfoo2.so | grep Type
Type: DYN (Shared object file)
E finalmente a combinação dos dois objetos compartilhados, libfoo2.so e libfoo1.so.
# gcc -shared -m32 -o libfoo3.so libfoo2.so libfoo1.so
# readelf -h libfoo3.so | grep Type
Type: DYN (Shared object file)
Combinado com um executável ou com outro objeto compartilhado para criação da imagem do processo pelo dynamic linker.
Este é o caso do nosso programa1 que ao ser executado é combinado, previamente a sua inicialização, com os demais arquivos-objeto compartilhados, através da ld-linux.so. Isso também ocorre com as próprias bibliotecas compartilhadas ao serem carregadas pelo sistema.
Core Dump
Um
core dump (
memory dump, system dump) é um arquivo-objeto contendo o estado da memória de um determinado programa, produzido pelo sistema geralmente quando aquele termina anormalmente (
crashed).
Vejamos, como usuário
root.
# gcc -m32 coredump.c -o coredump
# ulimit -c
0
# ulimit -c unlimited
# ulimit -c
unlimited
# ./coredump
Falha de segmentação (imagem do núcleo gravada)
Geralmente, o dump é salvo na pasta atual com o nome de
core. A localização e formato do nome do dump podem ser modificados no arquivo
/proc/sys/kernel/core_pattern. Mais informações:
man core.
# file core
core: ELF 32-bit LSB core file Intel 80386, version 1 (SYSV), SVR4-style, from './coredump'
Se estiverem utilizando Arch Linux, como foi o meu caso, faz-se necessário extrair o core dump de um sistema de journaling utilizado pelo systemd.
# systemd-coredumpctl | tail
...
Sex 2013-05-31 07:41:01 BRT 447 0 0 11 /home/uzumaki/git/hb/desconstruindo/coredump
# systemd-coredumpctl dump -o core
TIME PID UID GID SIG EXE
Sex 2013-05-31 07:41:01 BRT 447 0 0 11 /home/uzumaki/git/hb/desconstruindo/coredump
More than one entry matches, ignoring rest.
# file core
core: ELF 32-bit LSB core file Intel 80386, version 1 (SYSV), SVR4-style, from './coredump'
Um exemplo de uso do core dump seria com o gdb para se investigar a causa do crash.
# gdb -q ./coredump core
Reading symbols from /home/uzumaki/git/hb/desconstruindo/coredump...(no debugging symbols found)...done.
[New LWP 447]
warning: Could not load shared library symbols for linux-gate.so.1.
Do you need "set solib-search-path" or "set sysroot"?
Core was generated by `./coredump'.
Program terminated with signal 11, Segmentation fault.
#0 0x4c4b4a49 in ?? ()
(gdb) backtrace
#0 0x4c4b4a49 in ?? ()
#1 0x504f4e4d in ?? ()
#2 0x54535251 in ?? ()
#3 0x58575655 in ?? ()
#4 0xf7005a59 in ?? ()
...
Pode ser visto acima que a falha na segmentação ocorreu por conta do overflow dos caracteres.
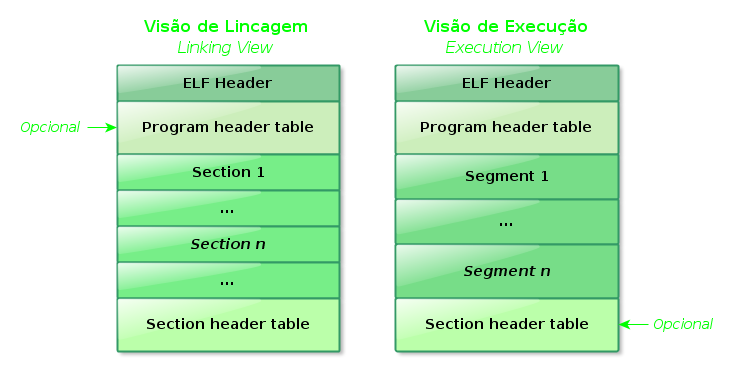
Estrutura ELF (Crystal Bones, Wood Bones, ...)
O formato ELF provê visões paralelas do conteúdo do binário que refletem as diferentes necessidades ao se lincar e ao se executar um programa. Inicialmente estudaremos a Visão de Lincagem.
Na estrutura há apenas um componente com localização fixa, o
ELF Header que se encontra no offset zero do arquivo-objeto. Nele são armazenadas as informações que descrevem a organização do restante do arquivo.
A
Program header table instrui o sistema como criar uma imagem de processo, portanto é um componente obrigatório nos arquivos-objeto executáveis e nos compartilhados; já os relocáveis não fazem uso dela.
As
Sections contemplam a massa de informação do arquivo-objeto utilizada na visão de lincagem, como instruções, dados, tabela de símbolos, informação de relocação, dentre outros.
A
Section header table contém informações descritivas das sections do objeto. Nela, para cada section, há uma entrada que fornece dados como nome, tamanho, dentre mais. Na lincagem o arquivo-objeto a ser combinado deve obrigatoriamente conter tal tabela. Outros arquivos-objetos podem ou não a conter.
Tipos de Dados (Not dices)
Seguem os tipos usados para a representação de dados nos arquivo-objetos ELF.
Criei o
elfdatatypes para mostrar o tamanho dos tipos em ambas arquiteturas.
ELF Header (Game Master)
Existem dois tipos de ELF header em
/usr/include/elf.h: Elf32_Ehdr e Elf64_Ehdr. Seus nomes são contrações em inglês (_Ehdr -> Elf header). ;)
Segue estrutura em C.
Verifiquemos o tamanho do ELF Header do programa1.
# readelf -h programa1 | grep this
Size of this header: 52 (bytes)
O posicionamento do ELF Header, como já citado, sempre será no offset zero do arquivo-objeto, no entanto seu tamanho dependerá da arquitetura: 32 bits (52 bytes); 64 bits (64 bytes).
Vejamos os 52 bytes relativos ao ELF Header 32.
0000000: 7f45 4c46 0101 0100 0000 0000 0000 0000 .ELF............
0000010: 0200 0300 0100 0000 0083 0408 3400 0000 ............4...
0000020: f007 0000 0000 0000 3400 2000 0800 2800 ........4. ...(.
0000030: 1e00 1b00 ....
Em conformidade com a estrutura Elf32_Ehdr, os 16 primeiros bytes são concernentes à identificação do arquivo-objeto (e_ident[16]). Se somarmos o tamanho dos tipos que se seguem (Elf32_Half e_type [2 bytes], Elf32_Half e_machine [2 bytes], Elf32_Word e_version [4 bytes]), chegaremos ao offset 24 que é referente ao entry point (0083 0408).
# readelf -h programa1 | grep Entry
Entry point address: 0x8048300 (00830408 em ordem inversa)
Antes de finalizarmos, para não ficar nenhum dissabor, vejamos um código em C (
elfentry) que lê o valor Entry Point do arquivo-objeto programa2.
# gcc -m32 elfentry.c -o elfentry
# ./elfentry
Entry Point: 0x8048080
# readelf -h programa2 | grep Entry
Entry point address: 0x8048080
Ficamos por aqui. No próximo encontro, esmiuçaremos a estrutura ElfN_Ehdr.
Até lá! o/
Mais Informações
ELF - Wikipedia
Elf (another kind) - Wikipedia
ABI - System V Application Binary Interface - SCO
The ELF Object File Format - Introduction - Linux Journal
The ELF Object File Format by Dissection - Linux Journal
Dissecando ELF - Felipe Pena
Linker (computing) - Wikipedia
Relocation (computing) - Wikipedia
Loader (computing)